
Sarvam AI, or what we call the OpenAI of India, is probably one of the most celebrated startups by Indian developers. Its focus on Indian languages and open source philosophy has been the cornerstone for AI development in India.
Recently, at Sarvam’s recent launch event, the company announced Sarvam 2B, its open source foundational model trained on 4 trillion tokens of data with 50% of it in 10 Indic languages.
According to co-founder Vivek Raghavan, Sarvam 2B is among other small language models in the market, such as Microsoft’s Phi-3, Meta’s Llama 3, and Google’s Gemma Models, which were all decent enough for Indic AI development.
But is Sarvam 2B really good enough for Indic AI developers?
First, to clear the air, the model uses a slightly modified Llama architecture, but is trained from scratch. This means there is no continued pre-training or distillation, making it the first foundational model built entirely for Indic languages.
We can also call it an ‘Indic Llama trained from scratch’. This is several steps ahead of the company’s earlier approach of building OpenHathi, which was a model fine-tuned on top of Llama 2.
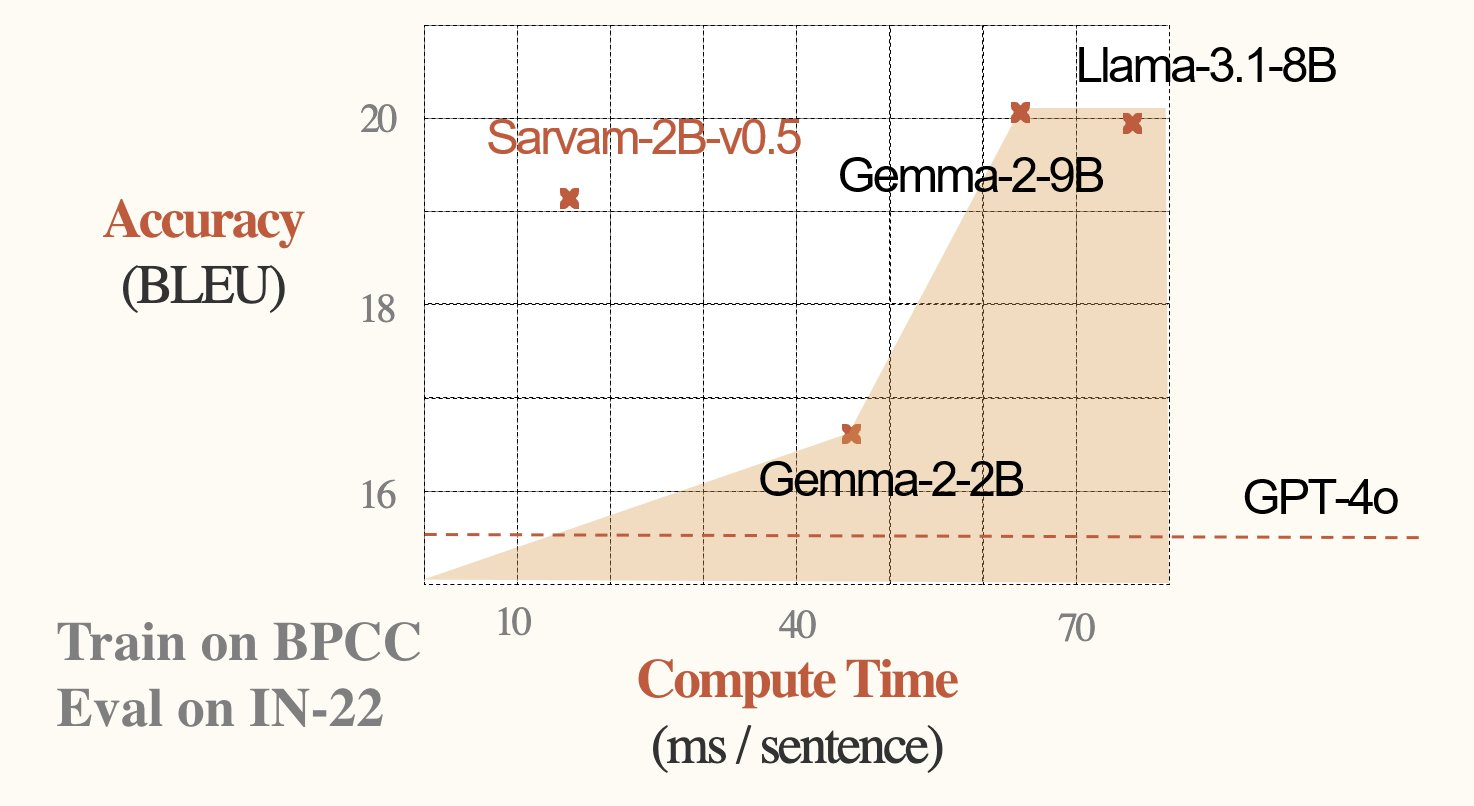
When compared to other models, Sarvam 2B outperforms GPT-4o and gives tough competition to Llama 3.1-8B and Gemma-2-9B in speed and accuracy for Indic languages.
The End of Indic Llama?
Models from Google, Meta, or OpenAI, have been increasingly trying to do better at Indic language translation and inference, but have been failing big time. Indian developers have been fine-tuning these models on billions of tokens of Indian language data, but the quality hasn’t necessarily improved.
Plus, these models have rarely been adopted for any production. “The best thing about Sarvam’s 2B model is that it puts an end to the Indic Llama garbage,” said Raj Dabre, a prominent researcher at NICT in Kyoto and a visiting professor at IIT Bombay.
The best thing about Sarvam’s 2B model is that it puts an end to the IndicLLaMa garbage. Thank God I don’t need to see yet another llama model fine tuned on 1B to 5B tokens of monolingual data and being passed of as something groundbreaking. 1B tokens? It does nothing.
— Raj Dabre (@prajdabre1) August 19, 2024
Pratik Desai, the founder of KissanAI, agrees with Dabre and said that none of those models were useful for production. He still has those same doubts about Sarvam 2B, even though it is a great stepping stone towards better Indic models.
“I doubt it will be used in production. Actually none of the 2B models are good enough to serve paid customers,” said Desai, adding that even models such as Gemma 2B are not useful – not even for English use cases.
Desai further explained that LLMs with 2 billion parameters struggle with following consistency and instructions even for summarisation, and are only good enough as helper models. But since Sarvam is also planning to release more versions in the future, these issues might get resolved eventually.
Regardless, the small size of the models make them useful for edge use cases and on-device LLMs. This, along with an audio model called Shuka released by Sarvam, would be helpful for the developer community to experiment with. But taking these models into production is still a hard decision to make as the output can become unreliable for several use cases, as is the case with other English models of the same size.
Along with this, the company also released Samvaad-Hi-v1 dataset, a collection of meticulously curated 100,000 high-quality English, Hindi, and Hinglish conversations, which is an invaluable resource for researchers and developers.
A Good Start
One of the key aspects of Sarvam 2B’s brilliant performance is it is completely trained on synthetic data, which is similar to Microsoft’s Phi series of models. Even though the debate around using synthetic data is still on, Raghavan said that it is essential to use synthetic data for Indian languages as the data is not available on the open web.
Furthermore, using synthetic data generated by the Sarvam 2B model would also help in improving the model’s capabilities in the future, or would make it run in circles.
Raghavan has also said that the cost of running Sarvam 2B would be a tenth of other models in the industry. With APIs and Sarvam Agents in the pipeline, it is clear that Sarvam’s sovereign AI approach is helping them build great models for Indian developers.
Images are for reference only.Images and contents gathered automatic from google or 3rd party sources.All rights on the images and contents are with their original owners.
Comments are closed.